
This week I’ve been working on support for my output template language in my on-line IDE. The IDE itself is basically a fairly old version of dock-spawn-ts, combined with Microsoft’s Monaco editor, with my own framework and configuration language. To make it work well with the template language, I’ve added a way to easily add language specific functions and custom lexers to Monaco via my framework. I’ve also been improving the framework’s support for the ‘diff’ mode in Monaco.
In any generative programming tool, turning the data structure created by the parser into source code in the target language is the final step, and this is the purpose of my template language. I’ve found surprisingly little written about this aspect of generative programming: there is literature from the Model Driven Engineering community, but I’ve not found much from from other researchers using DSLs. Maybe I’ve not been using the right search terms, or possibly it is seen as a solved problem, not worth writing about. (Or, just possibly, most people aren’t very proud of their work, and don’t want to publicise it too much…)
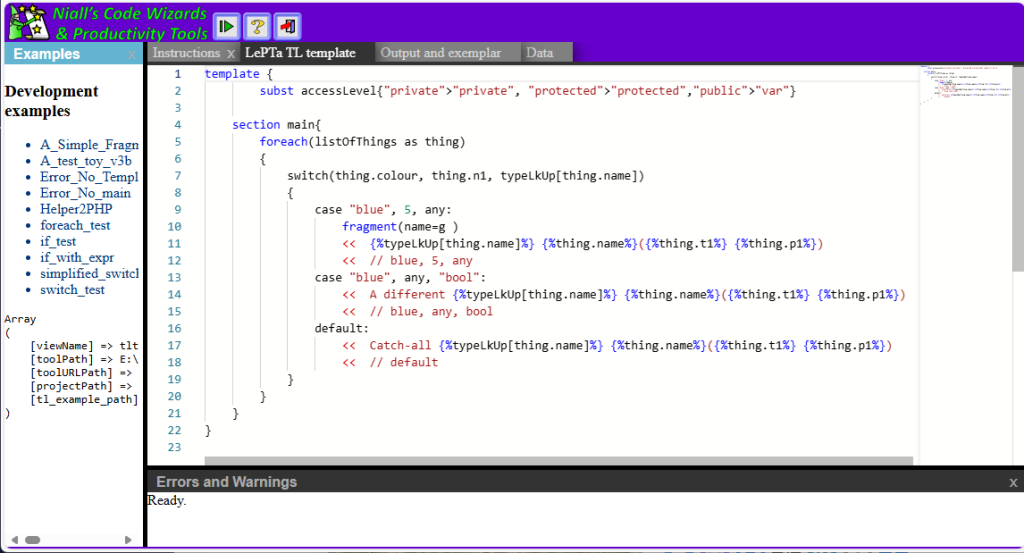
Like most aspect of my generative programming tools, my code generation has gone through a few iterations. My first attempts just used lots of print statements, and after a while I wrote a trivial tool to turn fragments of exemplar output into functions full or print statements to help write these. This was an adequate approach for simple tools, but the code was horrible to maintain. My next iteration was based on a template library, originally written for a QTI (XML) question editor. This had fields to be replaced, and also the ability to loop whist iterating over an array and incrementing a variable. As a code generation template language it evolved considerably, gaining callable subsections called ‘fragments’ which were passed a reference to a location in the input data structure, and increased structural elements such as foreach and case statements. Rather than all commands being inside in-line template fields, control lines were added, which aided readability. In the example below these start with two percent signs (something that WordPress doesn’t like 🙁 )
This template language sufficed for a long time, but I always felt it needed improved. Although better than the previous attempts, maintainability was still not great. In addition, templates are not always the best approach for every part of a project – sometimes preparing section with conventional code would just be neater.
Another issue with the this template language is the way white-space is supported – the leading white-space for control lines and output is unrelated. In practice I found that not using leading white-space on control lines was less unreadable than having an awkward mix. For languages like PHP and C# it would be possible to just stick with the best layout for the template control lines, and prettify the output, but I found that annoying, and it wouldn’t work for Python.
What I have been working on supporting in the IDE is a new version – a complete rewrite that mixes templates and conventional code as required, and sorts the white-space problem by making the output lines the delimited ones, using a C++ stream operator like syntax. I’ve also added a concept of ‘local variables’ that can be used for the details where templates don’t really work. The biggest change underneath though, is that this is now parsed using a conventional parser, rather than just scanning for template field delimiters, and processing the results.
In the IDE, I’ve added a way to bind keystrokes to processing for different file types. For my template files, the enter key, as well as preserving leading white-space, as is normal in a programming editor, now includes my template output indicator (<<) in that. The key combination Alt+O now converts the current selection to ‘output’, i.e. it puts the template output indicator at the start of each line in the current selection.
Up ’til now I’ve been developing and testing this language in a rather basic test program that is great for checking details, but awkward for editing non-trivial sized examples. The next step is using the IDE to develop a large example, and that will be when I really find out if I’ve solved the template maintainability challenge.
1 thought on “Turning data into code”